How to connect to ClickHouse with Python using SQLAlchemy
Guide about how to interact to ClickHouse database from the famous python library SQLAlchemy

Introduction
ClickHouse is one of the fastest opensource databases in the market and it claims to be faster than Spark. At WhiteBox we’ve tested this hypothesis with a +2 billion rows table and we can assure you it is! Our tests performed 3x faster for a complex aggregation with several filters.
Regarding this tutorial, all code and steps in this post has been tested in May 2021 and Ubuntu 20.04 OS, so please don’t be evil and don’t complain if the code does not work in September 2025 😅.
Requirements
The requirements for this integration are the following:
ClickHouse server: It can be installed quite easily following the official documentation. Current version (21.4.5.46).
Python libraries:
- SQLAlchemy: It can be installed using pip install SQLAlchemy==1.3.24.
- clickhouse-sqlalchemy: It can be installed using pip install clickhouse-sqlalchemy==0.1.6. There is another library “sqlalchemy-clickhouse”, but it does not support most of SQLAlchemy magic.
Setup
ClickHouse installation
This tutorial can be tested against any ClickHouse database. However, in order to get a local ClickHouse database to test the integration, it can be easily installed following the steps below:
sudo apt-get install apt-transport-https ca-certificates dirmngr
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E0C56BD4
echo "deb https://repo.clickhouse.tech/deb/stable/ main/" | sudo tee \
/etc/apt/sources.list.d/clickhouse.list
sudo apt-get update
sudo apt-get install -y clickhouse-server clickhouse-client
sudo service clickhouse-server start
Running command “clickhouse-client” on the shell ensure you that your ClickHouse installation is properly working. Besides, it can help you debug the SQLAlchemy DDL.
Python environment
These are the Python libraries that are required to run the all the code in this tutorial:
pip install SQLAlchemy==1.3.24
pip install clickhouse-sqlalchemy==0.1.6
Integration
SQLAlchemy setup
The following lines of code perform the SQLAlchemy standard connection:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
conn_str = 'clickhouse://default:@localhost/default'
engine = create_engine(conn_str)
session = sessionmaker(bind=engine)()
DDL
Create a new database
from sqlalchemy import DDL
database = 'test'
engine.execute(DDL(f'CREATE DATABASE IF NOT EXISTS {database}'))
It is possible to test the current databases in ClickHouse from the command line connection using the command “SHOW DATABASES”. The following output should display on screen:
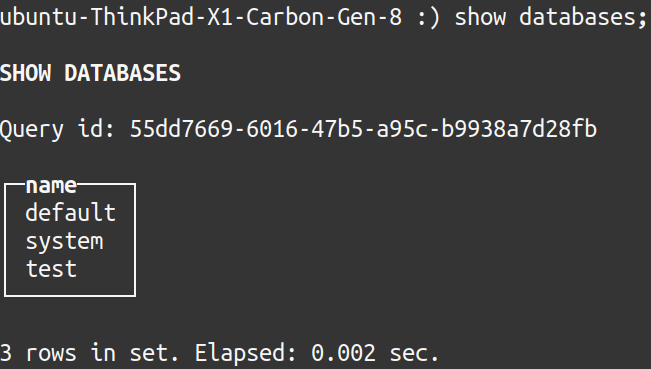
Create a new table
The following steps show how to create a MergeTree engine table in ClickHouse using the SQLAlchemy ORM model.
ORM model definition
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Date
from clickhouse_sqlalchemy import engines
Base = declarative_base()
class NewTable(Base):
__tablename__ = 'new_table'
__table_args__ = (
engines.MergeTree(order_by=['id']),
{'schema': database},
)
id = Column(Integer, primary_key=True)
var1 = Column(String)
var2 = Column(Date)
DDL
NewTable.__table__.create(engine)
A new table should appear in the new database:
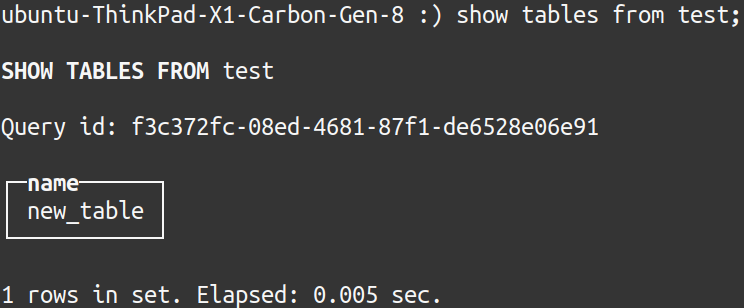
SQL
INSERT
from datetime import date
for i in range(1000):
row = NewTable(id=i, var1=f'test_str_{i}', var2=date(2021, 5, 3))
session.add(row)session.commit()
SELECT
session.query(NewTable).filter(NewTable.id >= 500).first().id
session.query(NewTable).filter_by(var1='test_str_2').first().id
Conclusions
Should ClickHouse replace traditional databases like Postgres, MySQL, Oracle? Definitively no. These databases have a lot of features that ClickHouse doesn’t currently have nor it is intended to have in the future (primary key basic concepts, unique columns…). It can be considered an analytics database but not a fully functioning transactional one.
However, ClickHouse speed is so amazing that it should be definitively the GOTO when there is a huge amount of tabular data.